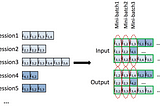
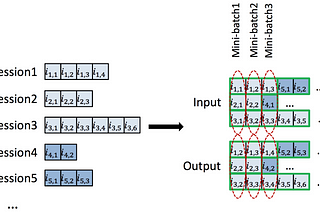
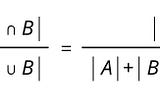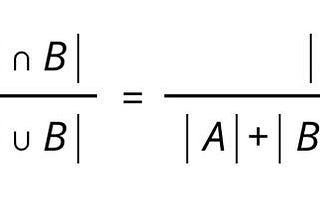Let's reproduce NanoGPT with Jax (Part 2) 175k->1350k tokens/sec in Single GPUenable Mixed Precision Training, Gradient Checkpointing, Gradient Clipping, and Gradient Accumulation etc for 1350k tokens/secAug 4, 20241Aug 4, 20241
Published inTDS ArchiveLet’s reproduce NanoGPT with JAX!(Part 1)Part 1: Build 124M GPT2 with JAX. Part 2: Optimize the training speed in Single GPU. Part 3: Multi-GPU Training in Jax.Jul 21, 20241Jul 21, 20241
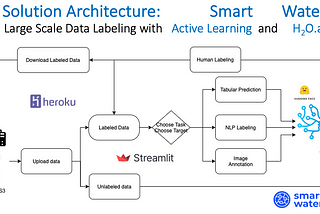
Published inAnalytics VidhyaSmart Water: Data Labeling with Active Learning And H2O.aiIntuitionMay 16, 20211May 16, 20211
Published inAnalytics VidhyaML Code Dive: K-Nearest NeighborsML Code Dive is a series of articles to deep dive machine learning algorithms without any ML libraries. It not only allows you to better…Apr 9, 2021Apr 9, 2021
Published inDataDrivenInvestorTraining the Lunar Lander Agent With Deep Q-Learning and Its variantsAbstractMar 22, 20211Mar 22, 20211
Published inDataDrivenInvestorML System Design Case: Recommend Restaurant in UberEatsTL;DR: the article shows a framework to solve a ML System design Case Study, And we use UberEats ReCommendation as an Example to show the…Mar 22, 2021Mar 22, 2021
Published inDataDrivenInvestorRethinking the right metrics for fraud detectionThe precision, recall, F1-score may not really work…Aug 6, 20192Aug 6, 20192
Published inDataDrivenInvestorRecommendation System: A problem statement viewThree types of problem statement on recommendation system.Jun 17, 2019Jun 17, 2019
Published inDataDrivenInvestorEmbeddings at eCommercePower personalization with deep learning and pre-trained product embeddingsMay 1, 20193May 1, 20193
What determines a good data scientist?In the big data world, more and more people hope to be a data scientist, utilizing the power of data and machine learning to solve real…Mar 16, 2019Mar 16, 2019